登录
/
注册
首页
论坛
其它
首页
科技
业界
安全
程序
广播
Follow
关于
导读
排行榜
资讯
发帖说明
登录
/
注册
账号
自动登录
找回密码
密码
登录
立即注册
搜索
搜索
关闭
CSDN热搜
程序园
精品问答
技术交流
资源下载
本版
帖子
用户
软件
问答
教程
代码
写记录
写博客
小组
VIP申请
VIP网盘
网盘
联系我们
发帖说明
道具
勋章
任务
淘帖
动态
分享
留言板
导读
设置
我的收藏
退出
腾讯QQ
微信登录
返回列表
首页
›
业界区
›
安全
›
读数据自助服务实践指南:数据开放与洞察提效02洞察耗时 ...
读数据自助服务实践指南:数据开放与洞察提效02洞察耗时
[ 复制链接 ]
嶝扁
2025-6-1 00:09:08
猛犸象科技工作室:
网站开发,备案域名,渗透,服务器出租,DDOS/CC攻击,TG加粉引流
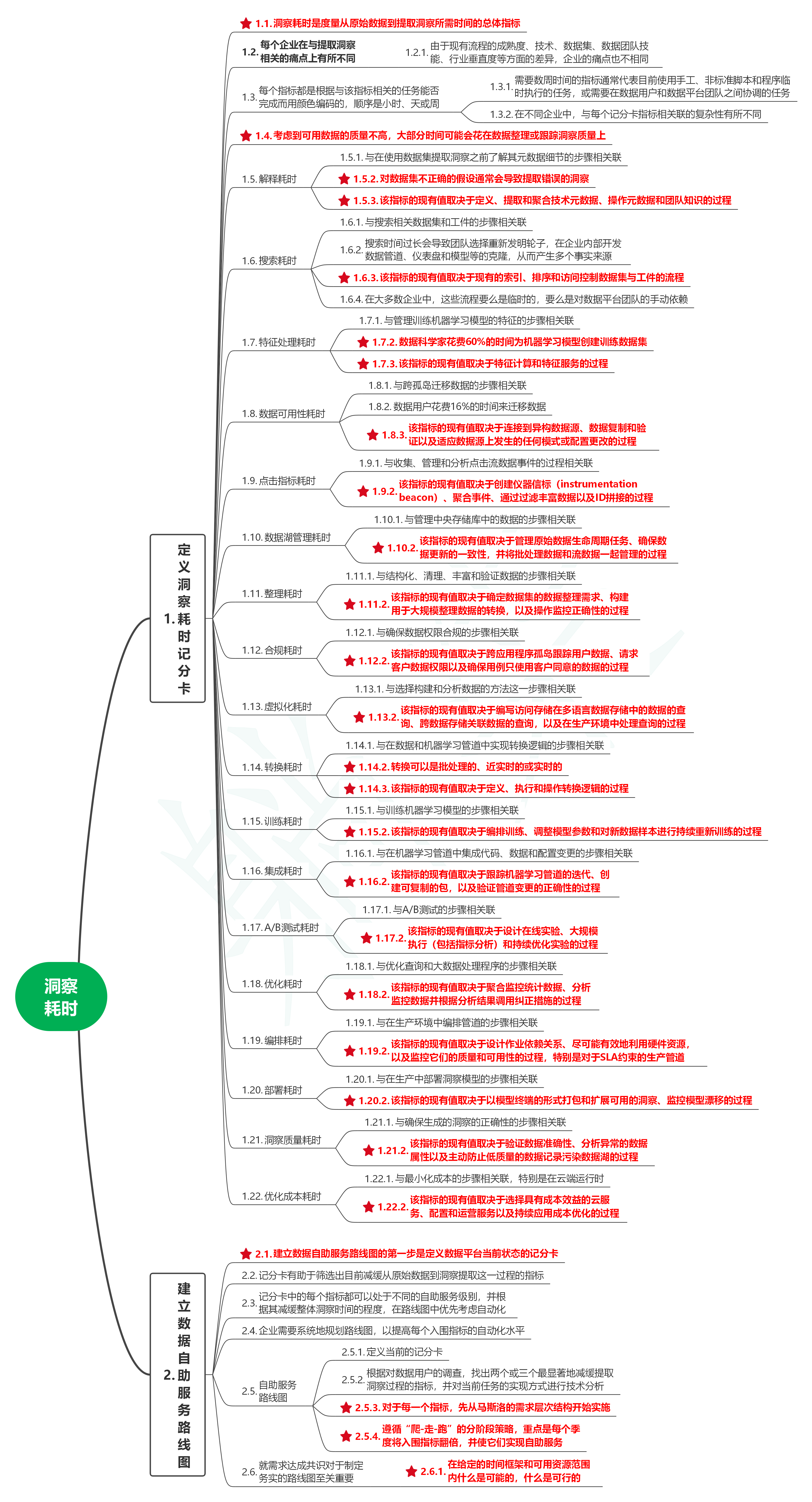
1. 定义洞察耗时记分卡
1.1. 洞察耗时是度量从原始数据到提取洞察所需时间的总体指标
1.2. 每个企业在与提取洞察相关的痛点上有所不同
1.2.1. 由于现有流程的成熟度、技术、数据集、数据团队技能、行业垂直度等方面的差异,企业的痛点也不相同
1.3. 每个指标都是根据与该指标相关的任务能否完成而用颜色编码的,顺序是小时、天或周
1.3.1. 需要数周时间的指标通常代表目前使用手工、非标准脚本和程序临时执行的任务,或需要在数据用户和数据平台团队之间协调的任务
1.3.2. 在不同企业中,与每个记分卡指标相关联的复杂性有所不同
1.4. 考虑到可用数据的质量不高,大部分时间可能会花在数据整理或跟踪洞察质量上
1.5. 解释耗时
1.5.1. 与在使用数据集提取洞察之前了解其元数据细节的步骤相关联
1.5.2. 对数据集不正确的假设通常会导致提取错误的洞察
1.5.3. 该指标的现有值取决于定义、提取和聚合技术元数据、操作元数据和团队知识的过程
1.6. 搜索耗时
1.6.1. 与搜索相关数据集和工件的步骤相关联
1.6.2. 搜索时间过长会导致团队选择重新发明轮子,在企业内部开发数据管道、仪表盘和模型等的克隆,从而产生多个事实来源
1.6.3. 该指标的现有值取决于现有的索引、排序和访问控制数据集与工件的流程
1.6.4. 在大多数企业中,这些流程要么是临时的,要么是对数据平台团队的手动依赖
1.7. 特征处理耗时
1.7.1. 与管理训练机器学习模型的特征的步骤相关联
1.7.2. 数据科学家花费60%的时间为机器学习模型创建训练数据集
1.7.3. 该指标的现有值取决于特征计算和特征服务的过程
1.8. 数据可用性耗时
1.8.1. 与跨孤岛迁移数据的步骤相关联
1.8.2. 数据用户花费16%的时间来迁移数据
1.8.3. 该指标的现有值取决于连接到异构数据源、数据复制和验证以及适应数据源上发生的任何模式或配置更改的过程
1.9. 点击指标耗时
1.9.1. 与收集、管理和分析点击流数据事件的过程相关联
1.9.2. 该指标的现有值取决于创建仪器信标(instrumentation beacon)、聚合事件、通过过滤丰富数据以及ID拼接的过程
1.10. 数据湖管理耗时
1.10.1. 与管理中央存储库中的数据的步骤相关联
1.10.2. 该指标的现有值取决于管理原始数据生命周期任务、确保数据更新的一致性,并将批处理数据和流数据一起管理的过程
1.11. 整理耗时
1.11.1. 与结构化、清理、丰富和验证数据的步骤相关联
1.11.2. 该指标的现有值取决于确定数据集的数据整理需求、构建用于大规模整理数据的转换,以及操作监控正确性的过程
1.12. 合规耗时
1.12.1. 与确保数据权限合规的步骤相关联
1.12.2. 该指标的现有值取决于跨应用程序孤岛跟踪用户数据、请求客户数据权限以及确保用例只使用客户同意的数据的过程
1.13. 虚拟化耗时
1.13.1. 与选择构建和分析数据的方法这一步骤相关联
1.13.2. 该指标的现有值取决于编写访问存储在多语言数据存储中的数据的查询、跨数据存储关联数据的查询,以及在生产环境中处理查询的过程
1.14. 转换耗时
1.14.1. 与在数据和机器学习管道中实现转换逻辑的步骤相关联
1.14.2. 转换可以是批处理的、近实时的或实时的
1.14.3. 该指标的现有值取决于定义、执行和操作转换逻辑的过程
1.15. 训练耗时
1.15.1. 与训练机器学习模型的步骤相关联
1.15.2. 该指标的现有值取决于编排训练、调整模型参数和对新数据样本进行持续重新训练的过程
1.16. 集成耗时
1.16.1. 与在机器学习管道中集成代码、数据和配置变更的步骤相关联
1.16.2. 该指标的现有值取决于跟踪机器学习管道的迭代、创建可复制的包,以及验证管道变更的正确性的过程
1.17. A/B测试耗时
1.17.1. 与A/B测试的步骤相关联
1.17.2. 该指标的现有值取决于设计在线实验、大规模执行(包括指标分析)和持续优化实验的过程
1.18. 优化耗时
1.18.1. 与优化查询和大数据处理程序的步骤相关联
1.18.2. 该指标的现有值取决于聚合监控统计数据、分析监控数据并根据分析结果调用纠正措施的过程
1.19. 编排耗时
1.19.1. 与在生产环境中编排管道的步骤相关联
1.19.2. 该指标的现有值取决于设计作业依赖关系、尽可能有效地利用硬件资源,以及监控它们的质量和可用性的过程,特别是对于SLA约束的生产管道
1.20. 部署耗时
1.20.1. 与在生产中部署洞察模型的步骤相关联
1.20.2. 该指标的现有值取决于以模型终端的形式打包和扩展可用的洞察、监控模型漂移的过程
1.21. 洞察质量耗时
1.21.1. 与确保生成的洞察的正确性的步骤相关联
1.21.2. 该指标的现有值取决于验证数据准确性、分析异常的数据属性以及主动防止低质量的数据记录污染数据湖的过程
1.22. 优化成本耗时
1.22.1. 与最小化成本的步骤相关联,特别是在云端运行时
1.22.2. 该指标的现有值取决于选择具有成本效益的云服务、配置和运营服务以及持续应用成本优化的过程
2. 建立数据自助服务路线图
2.1. 建立数据自助服务路线图的第一步是定义数据平台当前状态的记分卡
2.2. 记分卡有助于筛选出目前减缓从原始数据到洞察提取这一过程的指标
2.3. 记分卡中的每个指标都可以处于不同的自助服务级别,并根据其减缓整体洞察时间的程度,在路线图中优先考虑自动化
2.4. 企业需要系统地规划路线图,以提高每个入围指标的自动化水平
2.5. 自助服务路线图
2.5.1. 定义当前的记分卡
2.5.2. 根据对数据用户的调查,找出两个或三个最显著地减缓提取洞察过程的指标,并对当前任务的实现方式进行技术分析
2.5.3. 对于每一个指标,先从马斯洛的需求层次结构开始实施
2.5.4. 遵循“爬-走-跑”的分阶段策略,重点是每个季度将入围指标翻倍,并使它们实现自助服务
2.6. 就需求达成共识对于制定务实的路线图至关重要
2.6.1. 在给定的时间框架和可用资源范围内什么是可能的,什么是可行的
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
洞察
数据
自助
服务
实践
相关帖子
从海量数据到 AI 决策的落地方法
Kubernetes集群的搭建与DevOps实践(下)- 部署实践篇
搞懂“元数据”:给数据办一张“身份证”
期货数据对接指南,用于获取黄金、白银、原油等大宗商品的数据。
期货数据对接指南,用于获取黄金、白银、原油等大宗商品的数据。
ROS2核心概念之服务
上海专业防水补漏服务:国家一级资质,免费勘察,根治渗漏
北京上门收画服务权威推荐榜单
LLM应用实践: NoteBookLM初次使用
DBLens 的数据安全、登录方式与离线使用说明
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
相关推荐
业界
从海量数据到 AI 决策的落地方法
0
773
梁宁
2025-12-09
业界
Kubernetes集群的搭建与DevOps实践(下)- 部署实践篇
1
561
訾懵
2025-12-10
业界
搞懂“元数据”:给数据办一张“身份证”
1
991
费卿月
2025-12-11
安全
期货数据对接指南,用于获取黄金、白银、原油等大宗商品的数据。
0
821
府扔影
2025-12-11
安全
期货数据对接指南,用于获取黄金、白银、原油等大宗商品的数据。
1
31
赏勿
2025-12-11
业界
ROS2核心概念之服务
0
997
姨番单
2025-12-12
安全
上海专业防水补漏服务:国家一级资质,免费勘察,根治渗漏
0
946
山真柄
2025-12-13
安全
北京上门收画服务权威推荐榜单
0
223
裴竹悦
2025-12-13
业界
LLM应用实践: NoteBookLM初次使用
0
590
都淑贞
2025-12-15
安全
DBLens 的数据安全、登录方式与离线使用说明
0
102
郦惠
2025-12-16
回复
(1)
痕厄
4 天前
回复
使用道具
举报
照妖镜
程序园永久vip申请,500美金$,无限下载程序园所有程序/软件/数据/等
谢谢分享,试用一下
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
回复
本版积分规则
回帖并转播
回帖后跳转到最后一页
签约作者
程序园优秀签约作者
发帖
嶝扁
4 天前
关注
0
粉丝关注
20
主题发布
板块介绍填写区域,请于后台编辑
财富榜{圆}
3934307807
991124
anyue1937
9994893
kk14977
6845357
4
xiangqian
638210
5
韶又彤
9998
6
宋子
9983
7
闰咄阅
9993
8
刎唇
9993
9
俞瑛瑶
9998
10
蓬森莉
9951
查看更多
今日好文热榜
235
如何使用DashVector的多向量检索
268
【分析式AI】-朴素贝叶斯算法模型
214
【分析式AI】-朴素贝叶斯算法模型
933
【睿擎派】EtherCAT总线之IO模块读写
587
python3.13 3.14 新特性 好好好
782
Python新利器:用uv轻松管理venv虚拟环境和
953
Open-AutoGLM项目衍生自研app测试思路
180
.Net-Avalonia学习笔记(目录)
435
PoloAPI 绘画接口全攻略:从参数详解到实战
144
剑指offer-50、数组中重复的数字
178
嫌 Google 的 TCREI 太复杂?RACE 会更适合
975
Spring Boot中HTTP请求参数转换和请求体JSO
530
AI手机的“简单替换陷阱”与Hadoop、Cloude
474
用C#重现Gin风格:极简、效率与可扩展性设
243
AI运动识别插件-APP版新版特性速览
776
NetBox 自动化导入资产 - IP地址
80
在调度的花园里面挖呀挖
766
ACP:让 AI 编程工具配置从此告别碎片化 —
862
画高保真原型图用什么软件?产品经理与设计
67
企业数字化转型如何破局?看这三大招


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



