学习:智能体安全实践-360
概述
随着大模型推理能力提升,智能体(Agent)因其环境感知、自主决策和任务执行能力,在应用场景快速扩展的同时也暴露了显著的安全风险。报告由360漏洞研究院与清华大学合作,针对智能体全生命周期开展安全研究,覆盖开发框架、生态协同、沙箱隔离三大场景,挖掘20+开源项目漏洞(含15个CVE),揭示智能体面临的多维性、隐蔽性与系统性安全威胁。
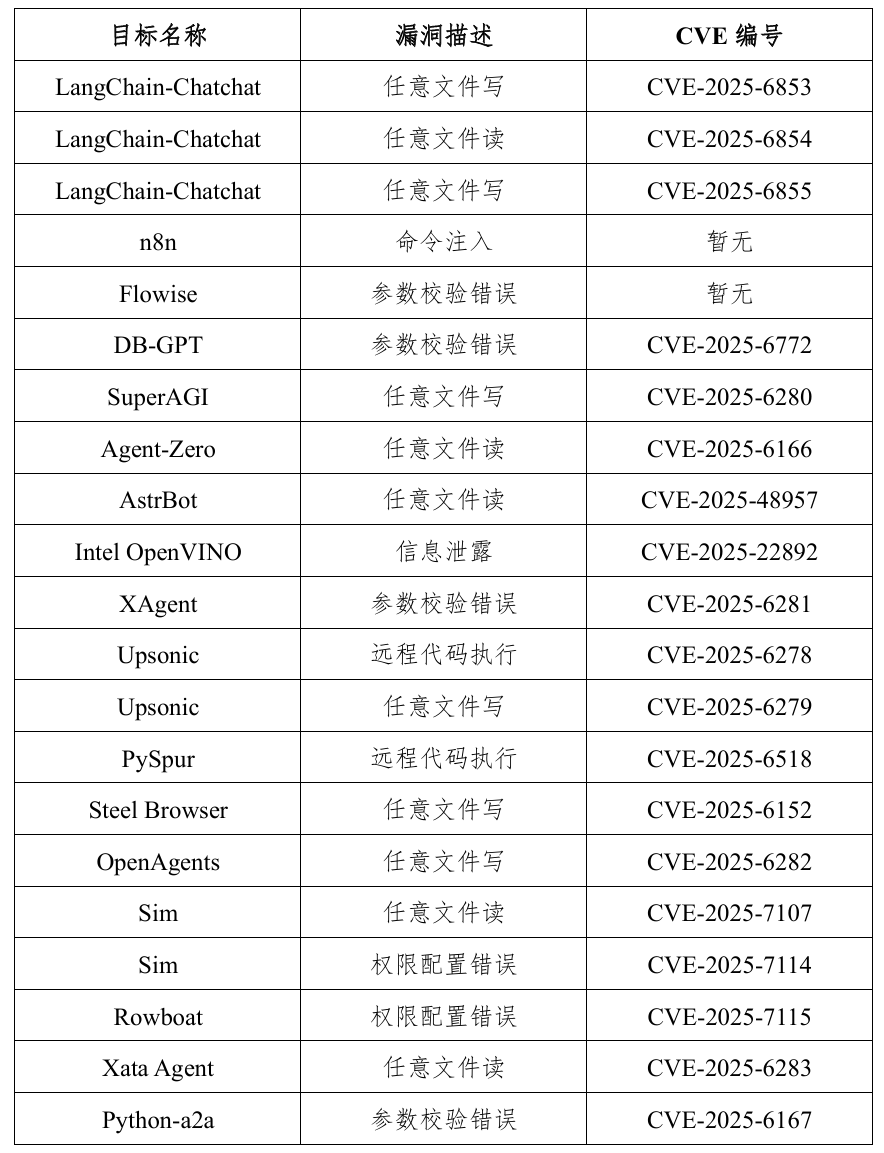
漏洞列表
报告公开20个漏洞案例,涉及主流开发框架、工具链及基础设施:
- 高风险漏洞类型:远程代码执行(如PySpur)、任意文件读写(如LangChain-Chatchat)、权限配置错误(如Sim)、参数校验缺失(如DB-GPT)。
- 典型目标:LangChain-Chatchat(3个CVE)、Upsonic(RCE+文件写)、AstrBot(任意文件读)等,部分漏洞尚无CVE编号但已构成实际威胁。
开发框架中的安全隐忧
开发框架抽象了模型、工具和编排模块,但其简化设计的代价是引入攻击面。
- 本地请求攻击
- 风险:框架本地服务(如Pyspur、Google ADK)默认绑定 0.0.0.0 或缺少认证,攻击者可通过浏览器跨域请求触发漏洞(如Jinja2模板注入)。
- 案例:
- Pyspur:未过滤的localhost请求致远程代码执行。
- Google ADK:硬编码绑定 0.0.0.0 + WebSocket无跨域限制,可静默操控Agent。
- 防御建议:默认绑定 127.0.0.1,增加服务层认证。
- 云上服务接口风险
- 风险:云端部署的框架接口(如Steel Browser)因代码逻辑与开源版一致,存在未修复漏洞。
- 案例:Steel Browser文件上传接口的 fileUrl 参数未过滤路径穿越字符,致任意文件写入。
- 防御建议:强化云服务接口的输入校验与权限控制。
智能体生态中的信任危机
【模型调用方、模型供给方、工具提供方、资源提供方等】多角色协同的开放生态面临信任链断裂风险:
- 调用链风险互嵌
- 大模型输出:诱导性Prompt可操控模型生成恶意指令(如伪造函数调用),需引入输出内容安全验证【内容合规检测、危险指令过滤、上下文一致性检查等】。
- 工具调用:
- Function calling流程拆解:
- 向大模型注册工具功能描述和接口定义信息等
- 对大模型工作时的输出进行解析,判断提取其中的工具调用需求,并以特定的参数形式调用指定工具接口
- 将工具运行结果返回给大模型
- MCP协议风险:Server投毒(恶意工具描述)、远程SSE模式遭中间人攻击、Client恶意请求触发传统漏洞(如SQL注入)。
- 多智能体协同:上下文投毒攻击(恶意智能体输出污染协同链路)。
- A2A协议风险:AgentCard字段(如AgentSkill)可能隐藏恶意提示词,影响调度决策。
- 脆弱的决策者
- 编排层依赖外部输入(如浏览器页面数据),易被注入对抗样本误导决策。
- 案例:Browser Use向模型传递未过滤的DOM元素描述,攻击者可注入指令接管Agent行为(如窃取文件并外传)。
- 防御建议:以零信任原则设计系统,强化模型输出的逻辑约束。
沙箱隔离中的盲区风险
隔离方案配置不当可能削弱防护效果:
- 差异化沙箱选择
- 按场景选择隔离层级:代码层(Deno)、进程层(Docker)、内核层(Firecracker/gVisor)。
- 云端沙箱服务(如E2B)简化部署但需关注供应商安全。
- 易忽视的暗面
- 案例1:OpenManus的Docker沙箱以 privileged=true 运行命令,赋予容器内核级权限,扩大逃逸面。
- 案例2:OpenHands采用Docker in Docker架构,挂载 docker.sock 致权限蔓延(开发容器可控制宿主机)。
- 防御建议:应用最小特权原则,精细配置沙箱权限与网络策略。
总结
智能体的安全挑战呈现三层矛盾:
- 开发框架:便捷性与安全性的平衡失衡,本地/云端接口均成攻击入口;
- 生态协作:开放协同需求与封闭安全要求的本质冲突,调用链信任机制亟待建立;
- 沙箱隔离:技术方案成熟但配置疏忽频发,需向“多层次防护体系”演进。 报告呼吁在工业控制、医疗等高危场景落地前,将安全性前置为智能体设计的核心指标,通过标准化协议、零信任架构和自动化检测机制构建可靠防线。
智能体安全需系统性治理,从单一漏洞修补转向覆盖“框架-生态-隔离”全链路的纵深防御,方能应对AI规模化应用中的未知威胁。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |










 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



