序
- 千行百业,自然语言处理、大模型、人工智能技术变革、数智化转型热潮进行得如火如荼,熟悉 Python 及其核心库————成为进入AI领域的基本能力。
- 数据处理与分析方面的 numpy 和 pandas 库首当其冲。
概述:Pandas
Pandas 是什么?
- Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
- Pandas 名字衍生自术语 "panel data"(面板数据)和 "
 ython data analysis"(Python 数据分析)。 ython data analysis"(Python 数据分析)。
- Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
- Pandas 一个强大的分析结构化数据的工具集,其基础是 Numpy(提供高性能的矩阵运算)。
起源
- Pandas诞生于2008年,它的开发者是Wes McKinney,一个量化金融分析工程师。
因为疲于应付繁杂的财务数据,Wes McKinney便自学Python,并开发了Pandas。大神就是这么任性,没有,就创造。
为什么叫作Pandas,其实这是“Python data analysis”的简写,同时也衍生自计量经济学术语“panel data”(面板数据)。
所以说,Pandas的诞生是为了分析金融财务数据,当然现在它已经应用在各个领域了。
Pandas 应用
- Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
- Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
- Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 功能
- Pandas 是数据分析的利器,它不仅提供了高效、灵活的数据结构,还能帮助你以极低的成本完成复杂的数据操作和分析任务。
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
数据结构
- Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)。
- Series 是一种类似于一维数组的对象,它由一组数据(各种 Numpy 数据类型)以及一组与之相关的数据标签(即索引)组成。
- DataFrame 是一个二维表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
- Pandas 是 Python 数据科学领域中不可或缺的工具之一,它的灵活性和强大的功能使得数据处理和分析变得更加简单和高效。
Series
- Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。
Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。
DataFrame
- DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。
DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引。
因此可以方便地进行行列选择、过滤、合并等操作。
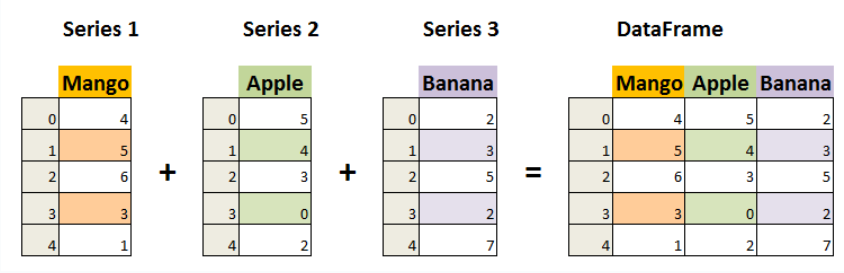
DataFrame 可视为由多个 Series 组成的数据结构:
下面这张图展示了两个 Series 对象相加得到一个 DataFrame 对象:
- DataFrame 由 Index、Key、Value 组成:
Demo
- import pandas as pd
- # 创建两个Series对象
- series_apples = pd.Series([1, 3, 7, 4])
- series_bananas = pd.Series([2, 6, 3, 5, 6])
- # 将两个Series对象相加,得到DataFrame,并指定列名
- df = pd.DataFrame({ 'Apples': series_apples, 'Bananas': series_bananas })
- # 显示DataFrame
- print(df)
out
- Apples Bananas
- 0 1.0 2
- 1 3.0 6
- 2 7.0 3
- 3 4.0 5
- 4 NaN 6
- import pandas as pd
- # 创建一个简单的 DataFrame
- data = {'Name': ['Google', 'Runoob', 'Taobao'], 'Age': [25, 30, 35]}
- df = pd.DataFrame(data)
- # 查看 DataFrame
- print(df)
out
- Name Age
- 0 Google 25
- 1 Runoob 30
- 2 Taobao 35
高效的数据结构:
- Series:一维数据结构,类似于列表(List),但拥有更强的功能,支持索引。
- DataFrame:二维数据结构,类似于表格或数据库中的数据表,行和列都具有标签(索引)。
数据清洗与预处理:
- Pandas 提供了丰富的函数来处理缺失值、重复数据、数据类型转换、字符串操作等,帮助用户轻松清理和转换数据。
数据操作与分析:
- 支持高效的数据选择、筛选、切片,按条件提取数据、合并、连接多个数据集、数据分组、汇总统计等操作。
- 可以进行复杂的数据变换,如数据透视表、交叉表、时间序列分析等。
数据读取与导出:
- 支持从各种格式的数据源读取数据,如 CSV、Excel、JSON、SQL 数据库等。
- 也可以将处理后的数据导出为不同格式,如 CSV、Excel 等。
数据可视化:
- 通过与 Matplotlib 和其他可视化工具的集成,Pandas 可以快速生成折线图、柱状图、散点图等常见图表。
时间序列分析:
- 支持强大的时间序列处理功能,包括日期的解析、重采样、时区转换等。
性能与优化:
- Pandas 优化了大规模数据处理,提供高效的向量化操作,避免了使用 Python 循环处理数据的低效。
- 还支持一些内存优化技术,比如使用 category 类型处理重复的数据。
Pandas 应用
- Pandas 在数据科学和数据分析领域中具有广泛的应用,其主要优势在于能够处理和分析结构化数据。
以下是 Pandas 的一些主要应用领域:
- 金融领域:金融机构使用 Pandas 来处理和分析股票市场数据、财务数据、交易数据等。Pandas 的灵活性和高效性使得金融分析师能够快速进行数据清洗、统计分析、建模等工作。
- 科学研究:科学研究领域经常涉及大量的实验数据、观测数据等,Pandas 提供了强大的工具来处理和分析这些数据,例如天文学、生物学、地球科学等领域。
- 企业数据分析:各种企业和组织都需要对业务数据进行分析,以支持决策和战略规划。Pandas 提供了处理和分析企业数据的功能,包括销售数据、客户数据、运营数据等。
- 社交媒体分析:社交媒体平台产生的海量数据需要进行分析来了解用户行为、趋势和情感倾向。Pandas 可以帮助分析师处理和分析社交媒体数据,进行用户行为分析、情感分析等。
- 医疗保健:医疗保健领域需要处理和分析大量的医疗数据,包括患者数据、临床试验数据、医疗图像数据等。Pandas 提供了处理和分析这些数据的工具,支持医疗研究和临床决策。
- 教育研究:教育领域可以利用 Pandas 来处理学生表现数据、教学评估数据、课程数据等,从而进行教育研究和改进教学质量。
- 市场营销:市场营销专业人员可以使用 Pandas 分析市场数据、客户数据、广告数据等,以制定营销策略和优化市场活动效果。
Pandas 在许多领域中都是一种强大而灵活的工具,为数据科学家、分析师和工程师提供了处理和分析数据的便捷方式。
Pandas 安装
- 安装 pandas 需要基础环境是 Python,Pandas 是一个基于 Python 的库,因此你需要先安装 Python,然后再通过 Python 的包管理工具 pip 安装 Pandas。
使用 pip 安装 pandas:
安装成功后,我们就可以导入 pandas 包使用:查看版本
- >>> import pandas
- >>> pandas.__version__ # 查看版本
- '1.1.5'
导入 pandas 一般使用别名 pd 来代替:
- >>> import pandas as pd
- >>> pd.__version__ # 查看版本
- '1.1.5'
- import pandas as pd
- mydataset = {
- 'sites': ["Google", "Runoob", "Wiki"],
- 'number': [1, 2, 3]
- }
- myvar = pd.DataFrame(mydataset)
- print(myvar)
out
- sites number
- 0 Google 1
- 1 Runoob 2
- 2 Wiki 3
- Series 是 Pandas 中的一个核心数据结构,类似于一个一维的数组,具有数据和索引。
- Series 可以存储任何数据类型(整数、浮点数、字符串等),并通过标签(索引)来访问元素。
- Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过标签来快速访问和操作数据。
Series 特点
- 一维数组:Series 中的每个元素都有一个对应的索引值。
- 索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
- 大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
- 操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
- 缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
- 自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。
CASE 创建Series 对象时,指定索引(Index)、名称(Name)以及值(Values)
- 我们可以使用 Pandas 库来创建一个 Series 对象,并且可以为其指定索引(Index)、名称(Name)以及值(Values):
- import pandas as pd
- # 创建一个Series对象,指定名称为'A',值分别为1, 2, 3, 4
- # 默认索引为0, 1, 2, 3
- series = pd.Series([1, 2, 3, 4], name='A')
- # 显示Series对象
- print(series)
- # 如果你想要显式地设置索引,可以这样做:
- custom_index = [1, 2, 3, 4] # 自定义索引
- series_with_index = pd.Series([1, 2, 3, 4], index=custom_index, name='A')
- # 显示带有自定义索引的Series对象
- print(series_with_index)
out
- 0 1
- 1 2
- 2 3
- 3 4
- Name: A, dtype: int64
- 1 1
- 2 2
- 3 3
- 4 4
- Name: A, dtype: int64
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
以下是关于 Pandas 中的 Series 的详细介绍。
创建 Series 对象
- 可以使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
- pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
- data:Series 的数据部分,可以是列表、数组、字典、标量值等。如果不提供此参数,则创建一个空的 Series。
- index:Series 的索引部分,用于对数据进行标记。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
- dtype:指定 Series 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
- name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。
- copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
- fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
demo
- import pandas as pd
- a = [1, 2, 3]
- myvar = pd.Series(a)
- print(myvar)
out
- 从上图可知: 如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
CASE 通过索引获取指定数组元素的值
demo 指定默认的索引,获取目标元素的值
- import pandas as pd
- a = [1, 2, 3]
- myvar = pd.Series(a)
- print(myvar[1]) # out: 2
demo 可以指定索引值,如下实例:
- import pandas as pd
- a = ["Google", "Runoob", "Wiki"]
- myvar = pd.Series(a, index = ["x", "y", "z"])
- print(myvar)
demo 根据索引值读取数据
- import pandas as pd
- a = ["Google", "Runoob", "Wiki"]
- myvar = pd.Series(a, index = ["x", "y", "z"])
- print(myvar["y"])
out
CASE 使用 key/value 对象来创建 Series 对象
- 我们也可以使用 key/value 对象,类似字典来创建 Series:
- import pandas as pd
- sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
- myvar = pd.Series(sites)
- print(myvar)
out
``log
1 Google
2 Runoob
3 Wiki
dtype: object
- > 从上图可知,**字典的 key** 变成了**索引值**。> 如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:```pythonimport pandas as pd
- sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
- myvar = pd.Series(sites)
- print(myvar)myvar2 = pd.Series(sites, index = [1, 2])print(myvar2)
out
- 1 Google
- 2 Runoob
- 3 Wiki
- dtype: object
- 1 Google
- 2 Runoob
- dtype: object
- import pandas as pd
- sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
- myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
- print(myvar)
out
- 1 Google
- 2 Runoob
- Name: RUNOOB-Series-TEST, dtype: object
方法名称功能描述index获取 Series 的索引values获取 Series 的数据部分(返回 NumPy 数组)head(n)返回 Series 的前 n 行(默认为 5)tail(n)返回 Series 的后 n 行(默认为 5)dtype返回 Series 中数据的类型shape返回 Series 的形状(行数)describe()返回 Series 的统计描述(如均值、标准差、最小值等)isnull()返回一个布尔 Series,表示每个元素是否为 NaNnotnull()返回一个布尔 Series,表示每个元素是否不是 NaNunique()返回 Series 中的唯一值(去重)value_counts()返回 Series 中每个唯一值的出现次数map(func)将指定函数应用于 Series 中的每个元素apply(func)将指定函数应用于 Series 中的每个元素,常用于自定义操作astype(dtype)将 Series 转换为指定的类型sort_values()
sort_values(ascending=True, inplace=Flase)对 Series 中的元素进行排序(按值排序)
ascending:默认为True升序排列,为Flase降序排序
inplace:是否修改原始的Seriessort_index()对 Series 的索引进行排序dropna()删除 Series 中的缺失值(NaN)fillna(value)填充 Series 中的缺失值(NaN)replace(to_replace, value)替换 Series 中指定的值cumsum()返回 Series 的累计求和cumprod()返回 Series 的累计乘积shift(periods)将 Series 中的元素按指定的步数进行位移rank()返回 Series 中元素的排名corr(other)计算 Series 与另一个 Series 的相关性(皮尔逊相关系数)cov(other)计算 Series 与另一个 Series 的协方差to_list()将 Series 转换为 Python 列表to_frame()将 Series 转换为 DataFrameiloc[]通过位置索引来选择数据loc[]通过标签索引来选择数据CASE 查看基本信息 / map 函数运算 / 累计求和 / 查找缺失值 / 排序
- import pandas as pd
- # 创建 Series
- data = [1, 2, 3, 4, 5, 6]
- index = ['a', 'b', 'c', 'd', 'e', 'f']
- s = pd.Series(data, index=index)
- # 查看基本信息
- print("索引:", s.index)
- print("数据:", s.values)
- print("数据类型:", s.dtype)
- print("前两行数据:\n", s.head(2))
- # 使用 map 函数将每个元素加倍
- s_doubled = s.map(lambda x: x * 2)
- print("元素加倍后:\n", s_doubled)
- # 计算累计和
- cumsum_s = s.cumsum()
- print("累计求和:\n", cumsum_s)
- # 查找缺失值(这里没有缺失值,所以返回的全是 False)
- print("缺失值判断:\n", s.isnull())
- # 排序
- sorted_s = s.sort_values()
- # sorted_s = s.sort_values(ascending=True)
- print("排序后的 Series:\n", sorted_s)
out
- 索引: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
- 数据: [1 2 3 4 5 6]
- 数据类型: int64
- 前两行数据:
- a 1
- b 2
- dtype: int64
- 元素加倍后:
- a 2
- b 4
- c 6
- d 8
- e 10
- f 12
- dtype: int64
- 累计求和:
- a 1
- b 3
- c 6
- d 10
- e 15
- f 21
- dtype: int64
- 缺失值判断: a False
- b False
- c False
- d False
- e False
- f False
- dtype: bool
- 排序后的 Series:
- a 1
- b 2
- c 3
- d 4
- e 5
- f 6
- dtype: int64
CASE 使用列表、字典或数组创建一个默认索引的 Series
- import numpy as np;
- import pandas as pd;
- # 使用列表创建 Series
- s = pd.Series([1, 2, 3, 4])
- print(s)
- # 使用 NumPy 数组创建 Series
- s = pd.Series(np.array([1, 2, 3, 4]))
- print(s)
- # 使用字典创建 Series
- s = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4})
- print(s)
out
- 0 1
- 1 2
- 2 3
- 3 4
- dtype: int64
- 0 1
- 1 2
- 2 3
- 3 4
- dtype: int64
- a 1
- b 2
- c 3
- d 4
- dtype: int64
- # 指定索引创建 Series
- s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
- # 获取值
- value = s[2] # 获取索引为2的值
- print(s['a']) # 返回索引标签 'a' 对应的元素
- # 获取多个值
- subset = s[1:4] # 获取索引为1到3的值
- # 使用自定义索引
- value = s['b'] # 获取索引为'b'的值
- # 索引和值的对应关系
- for index, value in s.items():
- print(f"Index: {index}, Value: {value}")
- # 使用切片语法来访问 Series 的一部分
- print(s['a':'c']) # 返回索引标签 'a' 到 'c' 之间的元素
- print(s[:3]) # 返回前三个元素
- # 为特定的索引标签赋值
- s['a'] = 10 # 将索引标签 'a' 对应的元素修改为 10
- # 通过赋值给新的索引标签来添加元素
- s['e'] = 5 # 在 Series 中添加一个新的元素,索引标签为 'e'
- # 使用 del 删除指定索引标签的元素。
- del s['a'] # 删除索引标签 'a' 对应的元素
- # 使用 drop 方法删除一个或多个索引标签,并返回一个新的 Series。
- s_dropped = s.drop(['b']) # 返回一个删除了索引标签 'b' 的新 Series
- # 算术运算
- result = series * 2 # 所有元素乘以2
- # 过滤
- filtered_series = series[series > 2] # 选择大于2的元素
- # 数学函数
- import numpy as np
- result = np.sqrt(series) # 对每个元素取平方根
- print(s.sum()) # 输出 Series 的总和
- print(s.mean()) # 输出 Series 的平均值
- print(s.max()) # 输出 Series 的最大值
- print(s.min()) # 输出 Series 的最小值
- print(s.std()) # 输出 Series 的标准差
- # 获取索引
- index = s.index
- # 获取值数组
- values = s.values
- # 获取描述统计信息
- stats = s.describe()
- # 获取最大值和最小值的索引
- max_index = s.idxmax()
- min_index = s.idxmin()
- # 其他属性和方法
- print(s.dtype) # 数据类型
- print(s.shape) # 形状
- print(s.size) # 元素个数
- print(s.head()) # 前几个元素,默认是前 5 个
- print(s.tail()) # 后几个元素,默认是后 5 个
- print(s.sum()) # 求和
- print(s.mean()) # 平均值
- print(s.std()) # 标准差
- print(s.min()) # 最小值
- print(s.max()) # 最大值
- # 使用字典创建 Series
- s = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4})
- print(s)
- print("result:\n", s > 2) # 返回一个布尔 Series,其中的元素值是否大于 2
out
- result:
- a False
- b False
- c True
- d True
- dtype: bool
- print(s.dtype) # 输出 Series 的数据类型
- s = s.astype('float64') # 将 Series 中的所有元素转换为 float64 类型
- Series 中的数据是有序的。
- 可以将 Series 视为带有索引的一维数组。
- 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
Pandas 数据结构 - DataFrame
- DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。
- DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
- DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
- DataFrame 提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。
- DataFrame 是一个非常灵活且强大的数据结构,广泛用于数据分析、清洗、转换、可视化等任务。
DataFrame 特点
- 二维结构: DataFrame 是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个 Series 对象组成的字典。
- 列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串或 Python 对象等。
- 索引:DataFrame 可以拥有行索引和列索引,类似于 Excel 中的行号和列标。
- 大小可变:可以添加和删除列,类似于 Python 中的字典。
- 自动对齐:在进行算术运算或数据对齐操作时,DataFrame 会自动对齐索引。
- 处理缺失数据:DataFrame 可以包含缺失数据,Pandas 使用 NaN(Not a Number)来表示。
- 数据操作:支持数据切片、索引、子集分割等操作。
- 时间序列支持:DataFrame 对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。
- 丰富的数据访问功能:通过 .loc、.iloc 和 .query() 方法,可以灵活地访问和筛选数据。
- 灵活的数据处理功能:包括数据合并、重塑、透视、分组和聚合等。
- 数据可视化:虽然 DataFrame 本身不是可视化工具,但它可以与 Matplotlib 或 Seaborn 等可视化库结合使用,进行数据可视化。
- 高效的数据输入输出:可以方便地读取和写入数据,支持多种格式,如 CSV、Excel、SQL 数据库和 HDF5 格式。
- 描述性统计:提供了一系列方法来计算描述性统计数据,如 .describe()、.mean()、.sum() 等。
- 灵活的数据对齐和集成:可以轻松地与其他 DataFrame 或 Series 对象进行合并、连接或更新操作。
- 转换功能:可以对数据集中的值进行转换,例如使用 .apply() 方法应用自定义函数。
- 滚动窗口和时间序列分析:支持对数据集进行滚动窗口统计和时间序列分析。
构造方法
- pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
- data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。
- index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
- columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
- dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
- copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
- Pandas DataFrame 是一个二维的数组结构,类似二维数组。
- Demo
- import pandas as pd
- data = [['Google', 10], ['Runoob', 12], ['Wiki', 13]]
- # 创建DataFrame
- df = pd.DataFrame(data, columns=['Site', 'Age'])
- # 使用astype方法设置每列的数据类型
- df['Site'] = df['Site'].astype(str)
- df['Age'] = df['Age'].astype(float)
- print(df)
也可以使用字典来创建:
- import pandas as pd
- data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
- df = pd.DataFrame(data)
- print (df)
out
- Site Age
- 0 Google 10
- 1 Runoob 12
- 2 Wiki 13
以下实例使用 ndarrays 创建,ndarray 的长度必须相同
- 如果传递了 index,则索引的长度应等于数组的长度。
如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
- ndarrays 可以参考: NumPy Ndarray 对象
Demo - 使用 ndarrays 创建
- import numpy as np
- import pandas as pd
- # 创建一个包含网站和年龄的二维ndarray
- ndarray_data = np.array([
- ['Google', 10],
- ['Runoob', 12],
- ['Wiki', 13]
- ])
- # 使用DataFrame构造函数创建数据帧
- df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])
- # 打印数据帧
- print(df)
out
- Site Age
- 0 Google 10
- 1 Runoob 12
- 2 Wiki 13
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):
Demo - 使用字典创建
- import pandas as pd
- data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
- df = pd.DataFrame(data)
- print (df)
out
- a b c
- 0 1 2 NaN
- 1 5 10 20.0
没有对应数据的部分为 NaN。
CASE 通过loc属性返回指定行的数据
- Pandas 可以使用 loc 属性返回指定行的数据
- 如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
- import pandas as pd
- data = {
- "calories": [420, 380, 390],
- "duration": [50, 40, 45]
- }
- # 数据载入到 DataFrame 对象
- df = pd.DataFrame(data)
- # 返回第一行
- print(df.loc[0])
- # 返回第二行
- print(df.loc[1])
out
- calories 420
- duration 50
- Name: 0, dtype: int64
- calories 380
- duration 40
- Name: 1, dtype: int64
- 注意:返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ ... ]] 格式,... 为各行的索引,以逗号隔开:
CASE 以字典创建DataFrame对象
- import pandas as pd
- data = {
- "calories": [420, 380, 390],
- "duration": [50, 40, 45]
- }
- # 数据载入到 DataFrame 对象
- df = pd.DataFrame(data)
- # 返回第一行
- print(df.loc[0])
- # 返回第一行和第二行
- print("\n", df.loc[[0, 1]])
out
- calories duration
- 0 420 50
- calories duration
- 0 420 50
- 1 380 40
注意:返回结果其实就是一个 Pandas DataFrame 数据。
如下实例:
- import pandas as pd
- data = {
- "calories": [420, 380, 390],
- "duration": [50, 40, 45]
- }
- df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
- print(df)
out
- calories duration
- day1 420 50
- day2 380 40
- day3 390 45
- Pandas 可以使用 loc 属性返回指定索引对应到某一行:
- import pandas as pd
- data = {
- "calories": [420, 380, 390],
- "duration": [50, 40, 45]
- }
- df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
- # 指定索引
- print(df.loc["day2"])
out
- calories 380
- duration 40
- Name: day2, dtype: int64
方法清单
方法名称功能描述head(n)返回 DataFrame 的前 n 行数据(默认前 5 行)tail(n)返回 DataFrame 的后 n 行数据(默认后 5 行)info()显示 DataFrame 的简要信息,包括列名、数据类型、非空值数量等describe()返回 DataFrame 数值列的统计信息,如均值、标准差、最小值等shape返回 DataFrame 的行数和列数(行数, 列数)columns返回 DataFrame 的所有列名index返回 DataFrame 的行索引dtypes返回每一列的数值数据类型sort_values(by)
按照指定列排序sort_index()
sort_index(by=None, axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True)按行索引排序
by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
axis:0按照行名排序;1按照列名排序
level:默认None,否则按照给定的level顺序排列---貌似并不是,文档
ascending:默认True升序排列;False降序排列
inplace:默认False,否则排序之后的数据直接替换原来的数据框
kind:排序方法,{"quicksort", "mergesort", "heapsort"}, default 'quicksort'。
na_position:缺失值默认排在最后dropna()删除含有缺失值(NaN)的行或列fillna(value)用指定的值填充缺失值isnull()判断缺失值,返回一个布尔值 DataFramenotnull()判断非缺失值,返回一个布尔值 DataFrameloc[]按标签索引选择数据iloc[]按位置索引选择数据at[]访问 DataFrame 中单个元素(比 loc[] 更高效)iat[]访问 DataFrame 中单个元素(比 iloc[] 更高效)apply(func)对 DataFrame 或 Series 应用一个函数applymap(func)对 DataFrame 的每个元素应用函数(仅对 DataFrame)groupby(by)分组操作,用于按某一列分组进行汇总统计pivot_table()创建透视表merge()合并多个 DataFrame(类似 SQL 的 JOIN 操作)concat()按行或按列连接多个 DataFrameto_csv()将 DataFrame 导出为 CSV 文件to_excel()将 DataFrame 导出为 Excel 文件to_json()将 DataFrame 导出为 JSON 格式to_sql()将 DataFrame 导出为 SQL 数据库query()使用 SQL 风格的语法查询 DataFrameduplicated()返回布尔值 DataFrame,指示每行是否是重复的drop_duplicates()删除重复的行set_index()设置 DataFrame 的索引reset_index()重置 DataFrame 的索引transpose()转置 DataFrame(行列交换)使用示例
- import pandas as pd
- # 创建 DataFrame
- data = {
- 'Name': ['Alice', 'Bob', 'Charlie', 'David'],
- 'Age': [25, 30, 35, 40],
- 'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
- }
- df = pd.DataFrame(data)
- # 查看前两行数据
- print(df.head(2))
- # 查看 DataFrame 的基本信息
- print("info:\n", df.info())
- # 获取描述统计信息
- print("describe:\n", df.describe())
- # 按列排序 (列名=年龄,排序方式=降序)
- df_sorted = df.sort_values(by='Age', ascending=False)
- print("df_sorted:\n", df_sorted)
- # 选择指定列
- print("Name, Age:\n", df[['Name', 'Age']])
- # 按索引选择行
- print("df.iloc[1:3]:\n", df.iloc[1:3]) # 选择第二到第三行(按位置)
- # 按标签选择行
- print("df.loc[1:2]:\n", df.loc[1:2]) # 选择第二到第三行(按标签)
- # 计算分组统计(按城市分组,计算平均年龄)
- print("groupby:\n", df.groupby('City')['Age'].mean())
- # 处理缺失值(填充缺失值)
- df['Age'] = df['Age'].fillna(30)
- # 导出为 CSV 文件
- df.to_csv('output.csv', index=False)
out
- Name Age City
- 0 Alice 25 New York
- 1 Bob 30 Los Angeles
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 4 entries, 0 to 3
- Data columns (total 3 columns):
- # Column Non-Null Count Dtype
- --- ------ -------------- -----
- 0 Name 4 non-null object
- 1 Age 4 non-null int64
- 2 City 4 non-null object
- dtypes: int64(1), object(2)
- memory usage: 228.0+ bytes
- info:
- None
- describe:
- Age
- count 4.000000
- mean 32.500000
- std 6.454972
- min 25.000000
- 25% 28.750000
- 50% 32.500000
- 75% 36.250000
- max 40.000000
- df_sorted:
- Name Age City
- 3 David 40 Houston
- 2 Charlie 35 Chicago
- 1 Bob 30 Los Angeles
- 0 Alice 25 New York
- Name, Age:
- Name Age
- 0 Alice 25
- 1 Bob 30
- 2 Charlie 35
- 3 David 40
- df.iloc[1:3]:
- Name Age City
- 1 Bob 30 Los Angeles
- 2 Charlie 35 Chicago
- df.loc[1:2]:
- Name Age City
- 1 Bob 30 Los Angeles
- 2 Charlie 35 Chicago
- groupby:
- City
- Chicago 35.0
- Houston 40.0
- Los Angeles 30.0
- New York 25.0
- Name: Age, dtype: float64
试验数据
- import pandas as pd
- import numpy as np
-
- # 生成DataFrame
- df= pd.DataFrame(np.arange(30).reshape((6,5)),
- columns=['A','B','C','D','E'])
- print(df)
- # 写入本地
- # df.to_excel("D:\\实验数据\\data.xls", sheet_name="data")
out
- A B C D E
- 0 0 1 2 3 4
- 1 5 6 7 8 9
- 2 10 11 12 13 14
- 3 15 16 17 18 19
- 4 20 21 22 23 24
- 5 25 26 27 28 29
- 访问列:使用列名作为属性或通过 .loc[]、.iloc[] 访问,也可以使用标签或位置索引。
- loc:通过行、列的名称或标签来索引
- iloc:通过行、列的索引位置来寻找数据
- # 通过列名访问
- print("column=A: `df['A']`\n", df['A'])
- ## 访问多个列
- # print("column=A,B: `df['A', 'B']`\n", df['A', 'B']) # 错误语法
- print("column=A,B: `df[['A', 'B']]`\n", df[['A', 'B']]) # 正确语法
- # 通过属性访问
- print("column=B: `df.B`\n", df.B)
- # 通过 .loc[] 访问列 by 列名
- print("column=A: `df.loc[:, 'A']`\n", df.loc[:, 'A'])
- # 通过 .iloc[] 访问列 by 列下标
- print("column=A: `df.iloc[:, 0]`\n", df.iloc[:, 0]) # 假设 'A' 是第一列
- # 访问单个元素
- print("`df['B'][0]`:",df['B'][0])
- print("`df.loc[ 0, "B"]`:", df.loc[ 0, "B"])
out
- column=A: `df['A']`
- 0 0
- 1 5
- 2 10
- 3 15
- 4 20
- 5 25
- Name: A, dtype: int64
- column=A,B: `df[['A', 'B']]`
- A B
- 0 0 1
- 1 5 6
- 2 10 11
- 3 15 16
- 4 20 21
- 5 25 26
- column=B: `df.B`
- 0 1
- 1 6
- 2 11
- 3 16
- 4 21
- 5 26
- Name: B, dtype: int64
- column=A: `df.loc[:, 'A']`
- 0 0
- 1 5
- 2 10
- 3 15
- 4 20
- 5 25
- Name: A, dtype: int64
- column=A: `df.iloc[:, 0]`
- 0 0
- 1 5
- 2 10
- 3 15
- 4 20
- 5 25
- Name: A, dtype: int64
- `df['B'][0]`: 1
- `df.loc[ 0, "B"]`: 1
- # 通过 .loc[] 访问行 by 行索引名/标签 (可自定义,默认是数值)
- print("row=2: `df.loc[1]`\n", df.loc[1]) # 访问第2行 | df.loc[1] 等效于 df.loc[1, :]
- #print("row=2: `df.loc[1, :]`\n", df.loc[1, :])
- print("df.loc[1:2]:\n", df.loc[1:2]) # 选择第二到第三行(按标签)
- # 通过 .iloc[] 访问列 by 行下标(位置)
- print("row=2: `df.iloc[1]`\n", df.iloc[1])
- # print("row=2: `df.iloc[1, :]`\n", df.iloc[1, :]) # 访问第2行 | df.iloc[1] 等效于 df.iloc[1, :]
- print("df.iloc[1:3]:\n", df.iloc[1:3]) # 选择第二到第三行(按位置)
- # 访问单个元素
- print("`df.loc[ 0, "B"]`:", df.loc[ 0, "B"])
- print("`df['B'][0]`:",df['B'][0])
out
- row=2: `df.loc[1]`
- A 5
- B 6
- C 7
- D 8
- E 9
- Name: 1, dtype: int64
- df.loc[1:2]:
- A B C D E
- 1 5 6 7 8 9
- 2 10 11 12 13 14
- row=2: `df.iloc[1]`
- A 5
- B 6
- C 7
- D 8
- E 9
- Name: 1, dtype: int64
- df.iloc[1:3]:
- A B C D E
- 1 5 6 7 8 9
- 2 10 11 12 13 14
- `df.loc[ 0, "B"]`: 1
- `df['B'][0]`: 1
- df= pd.DataFrame(
- np.arange(30).reshape((6,5))
- , columns=['A','B','C','D','E']
- );
- print(df);
- print( "前3行:\n", df.head(3) );
- print( "后3行:\n", df.tail(3) );
out
- A B C D E
- 0 0 1 2 3 4
- 1 5 6 7 8 9
- 2 10 11 12 13 14
- 3 15 16 17 18 19
- 4 20 21 22 23 24
- 5 25 26 27 28 29前3行: A B C D E0 0 1 2 3 41 5 6 7 8 92 10 11 12 13 14后3行: A B C D E3 15 16 17 18 194 20 21 22 23 245 25 26 27 28 29
- # 访问单个元素
- print("`df.loc[ 0, "B"]`:", df.loc[ 0, "B"])
- print("`df['B'][0]`:",df['B'][0])
out
- `df.loc[ 0, "B"]`: 1
- `df['B'][0]`: 1
- # 读取第1行到第3行,第B列到第D列这个区域内的值
- print("\n`df.loc[ 1:3, "B":"D"]`\n", df.loc[ 1:3, "B":"D"])
- # 按index和columns进行切片操作 : 读取第2、3行(即 [1+1,3+1),第3、4列(即: [2+1, 4+1) )
- print("`df.iloc[1:3, 2:4]`:\n", df.iloc[1:3, 2:4])
- # df.loc[ df.B > 6] 等价于 df[df.B > 6]
- print("`df.loc[ df.B > 6]`:\n", df.loc[ df.B > 6]) # 读取第B列中大于6的值
- # 切片操作 : 选择B,C,D,E四列区域内,B列大于6的值
- print("`df.loc[ df.B >6, ["B","C","D","E"]]`:\n", df.loc[ df.B > 6, ["B","C","D","E"]])
out
- `df.loc[ 1:3, "B":"D"]`
- B C D
- 1 6 7 8
- 2 11 12 13
- 3 16 17 18
- `df.iloc[1:3, 2:4]`:
- C D
- 1 7 8
- 2 12 13
- `df.loc[ df.B > 6]`:
- A B C D E
- 2 10 11 12 13 14
- 3 15 16 17 18 19
- 4 20 21 22 23 24
- 5 25 26 27 28 29
- `df.loc[ df.B >6, ["B","C","D","E"]]`:
- B C D E
- 2 11 12 13 14
- 3 16 17 18 19
- 4 21 22 23 24
- 5 26 27 28 29
关键函数: sort_index / sort_values
- dataFrameObject.sort_index(
- by=None,
- axis=0, level=None,
- ascending=True,
- inplace=False,
- kind='quicksort',
- na_position='last',
- sort_remaining=True
- )
- by:按照某一列或几列数据进行排序,但是by参数貌似不建议使用
- axis:0按照行名排序;1按照列名排序
- level:默认None,否则按照给定的level顺序排列---貌似并不是,文档
- ascending:默认True升序排列;False降序排列
- inplace:默认False,否则排序之后的数据直接替换原来的数据框
- kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。
- na_position:缺失值默认排在最后
- dataFrameObjecy.sort_values(
- by,
- axis=0,
- ascending=True,
- inplace=False,
- kind='quicksort',
- na_position='last'
- )
- by:字符串或者List;如果axis=0,那么by="列名";如果axis=1,那么by="行名"。
- axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,即纵向排序;如果为1,则是横向排序。
- ascending:布尔型,True则升序,如果by=['列名1','列名2'],则该参数可以是[True, False],即第一字段升序,第二个降序。
- inplace:布尔型,是否用排序后的数据框替换现有的数据框。
- kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。
- na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
试验数据
- import numpy as np
- import pandas as pd
- data = pd.DataFrame(
- np.arange(9).reshape(3,3)
- , index = ["0","2","1"]
- , columns = ["col_a","col_c","col_b"]
- )
out
- data
- col_a col_c col_b
- 0 0 1 2
- 2 3 4 5
- 1 6 7 8
- data.sort_index()
- col_a col_c col_b
- 0 0 1 2
- 1 6 7 8
- 2 3 4 5
- data.sort_index(ascending=False)
- col_a col_c col_b
- 2 3 4 5
- 1 6 7 8
- 0 0 1 2
- # axis : 0按照行名排序;1按照列名排序
- print( data.sort_index(axis=1) )
- Out:
- col_a col_b col_c
- 0 0 2 1
- 2 3 5 4
- 1 6 8 7
- print(data.sort_values(by="col_a"))
- # 等效于: print(data.sort_values(by="col_a", axis=0, ascending=True))
out
- col_a col_c col_b
- 0 0 1 2
- 2 3 4 5
- 1 6 7 8
- print( data.sort_values(by=['col_b','col_a']) )
out
- col_a col_c col_b
- 0 0 1 2
- 2 3 4 5
- 1 6 7 8
- 先按col_b列的值降序,再按col_a列的值升序排序
- print( data.sort_values(by=['col_b','col_a'], axis=0,ascending=[False,True]) )
out
- col_a col_c col_b
- 1 6 7 8
- 2 3 4 5
- 0 0 1 2
- print( data.sort_values(by='2',axis=1) ) # 第 2 +1 行
out
- col_a col_c col_b
- 0 0 1 2
- 2 3 4 5
- 1 6 7 8
- print( data.sort_values(by=['2','0'],axis=1, ascending=[False,True]) )
out
- col_b col_c col_a
- 0 2 1 0
- 2 5 4 3
- 1 8 7 6
创建 DataFrame
CASE 从字典创建 DataFrame
- import pandas as pd
- # 通过字典创建 DataFrame
- df = pd.DataFrame({'Column1': [1, 2, 3], 'Column2': [4, 5, 6]})
- df = pd.DataFrame(
- [[1, 2, 3], [4, 5, 6], [7, 8, 9]],
- columns=['Column1', 'Column2', 'Column3']
- )
- 从 NumPy 数组创建:提供一个二维 NumPy 数组。
- import numpy as np
- # 通过 NumPy 数组创建 DataFrame
- df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
- 从 Series 创建 DataFrame:通过 pd.Series() 创建。
- # 从 Series 创建 DataFrame
- s1 = pd.Series(['Alice', 'Bob', 'Charlie'])
- s2 = pd.Series([25, 30, 35])
- s3 = pd.Series(['New York', 'Los Angeles', 'Chicago'])
- df = pd.DataFrame({'Name': s1, 'Age': s2, 'City': s3})
- DataFrame 对象有许多属性和方法,用于数据操作、索引和处理,例如:shape、columns、index、head()、tail()、info()、describe()、mean()、sum() 等。
- # DataFrame 的属性和方法
- print(df.shape) # 形状
- print(df.columns) # 列名
- print(df.index) # 索引
- print(df.head()) # 前几行数据,默认是前 5 行
- print(df.tail()) # 后几行数据,默认是后 5 行
- print(df.info()) # 数据信息
- print(df.describe())# 描述统计信息
- print(df.mean()) # 求平均值
- print(df.sum()) # 求和
删除列:使用 drop 方法。- df_dropped = df.drop('Column1', axis=1)
- df_dropped = df.drop(0) # 删除索引为 0 的行
描述性统计:使用 .describe() 查看数值列的统计摘要。计算统计数据:使用聚合函数如 .sum()、.mean()、.max() 等。- df['Column1'].sum()
- df.mean()
重置索引:使用 .reset_index()。- df_reset = df.reset_index(drop=True)
- df_set = df.set_index('Column1')
使用布尔表达式:根据条件过滤 DataFrame。DataFrame 的数据类型
查看数据类型:使用 dtypes 属性。转换数据类型:使用 astype 方法。- df['Column1'] = df['Column1'].astype('float64')
合并:使用 concat 或 merge 方法。- # 纵向合并
- pd.concat([df1, df2], ignore_index=True)
- # 横向合并
- pd.merge(df1, df2, on='Column1')
- # 长格式转宽格式
- df_pivot = df.pivot(index='Column1', columns='Column2', values='Column3')
- # 宽格式转长格式
- df_melt = df.melt(id_vars='Column1', value_vars=['Column2', 'Column3'])
- DataFrame 支持对行和列进行索引和切片操作。
实例 : 索引和切片
print(df[['Name', 'Age']]) # 提取多列
print(df[1:3]) # 切片行
print(df.loc[:, 'Name']) # 提取单列
print(df.loc[1:2, ['Name', 'Age']]) # 标签索引提取指定行列
print(df.iloc[:, 1:]) # 位置索引提取指定列
注意事项
- DataFrame 是一种灵活的数据结构,可以容纳不同数据类型的列。
- 列名和行索引可以是字符串、整数等。
- DataFrame 可以通过多种方式进行数据选择、过滤、修改和分析。
- 通过对 DataFrame 的操作,可以进行数据清洗、转换、分析和可视化等工作。
Z FAQ for Pandas
Q: 使用基于 OpenPyXL 的 Pandas 读取 Excel 数据集?
- Python = 3.12
- Pandas = 2.2.3
内部依赖 openpyxl 组件
- #!/usr/bin/python3
- ## #!/usr/bin/python
- # -*- coding: UTF-8 -*-
- import pandas as pd;
- """
- Excel 文件 转 Parquet 文件
- """
- # 从 Excel 文件,读取信号数据集合
- def readDataset(excelFilePath):
- # 读取 Excel 文件
- df = pd.read_excel(excelFilePath, sheet_name=None)
- # 获取所有工作表的名称
- sheet_names = df.keys()
- # 将所有工作表的数据合并为一个 DataFrame
- combined_df = pd.concat(df.values(), ignore_index=True)
- return combined_df
- dataset = readDataset(excelFilePath="../dataset/signals.xlsx");
- print(dataset)
- https://pandas.pydata.org/
- https://github.com/pandas-dev/pandas
- [Python/数学] Numpy : 支持多维数组与矩阵运算的线性代数库 - 博客园/千千寰宇
- [Python/Java] 数据科学与人工智能开源库 - 博客园/千千寰宇
- [Excel/Python] OpenPyXl : Python 的 Excel 库 - 博客园/千千寰宇
X 参考文献
- Pandas 教程 - 菜鸟教程
- Pandas 数据结构 - Series - 菜鸟教程
- Pandas读取某列、某行数据——loc、iloc用法总结 - CSDN
本文作者: 千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |












 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



