探秘Transformer系列之(30)--- 投机解码
目录
- 探秘Transformer系列之(30)--- 投机解码
- 0x00 概述
- 0x01 背景
- 0x02 定义 & 历史
- 0x03 Blockwise Parallel Decoding
- 3.1 动机
- 3.2 思路
- 3.3 架构
- 3.4 训练
- 3.5 步骤
- 3.6 优化
- 3.7 收益
- 0x04 原理
- 4.1 动机
- 4.2 思路
- 4.3 对比
- 4.4 分类&设计
- 4.4.1 推测阶段的策略
- 4.4.2 验证阶段的策略
- 0x05 算法
- 5.1 总体流程
- 5.2 关键步骤
- 5.2.1 前置条件
- 5.2.2 第一步 - 采样
- 5.2.3 第二步 - 并行运行目标模型
- 5.2.4 第三步 - 计算接受的猜测token数量
- 5.2.5 第四步 - 调整概率分布
- 5.2.6 第五步 - 返回生成的结果
- 5.3 重点分析
- 5.3.1 并行验证
- 5.3.2 加速效果
- 5.3.3 调整分布
- 5.3.4 优化
- 0x06 实现
- 6.1 全局循环
- 6.2 外层逻辑
- 6.3 实施算法
- 0x07 Token Tree Verification
- 7.1 问题
- 7.1.1 采样多个序列
- 7.1.2 验证多个序列
- 7.2 思路
- 7.2.1 开山之作SpecInfer
- 7.2.2 如何组织树
- 7.3 Attention Mask
- 0xFF 参考
0x00 概述
投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。
下图左侧是自回归解码模型,右侧是投机解码机制。
从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。
注:
- 全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改此文章列表。cnblogs 探秘Transformer系列之文章列表
- 本系列是对论文、博客和代码的学习和解读,借鉴了很多网上朋友的文章,在此表示感谢,并且会在参考中列出。因为本系列参考文章太多,可能有漏给出处的现象。如果原作者或者其它朋友发现,还请指出,我在参考文献中进行增补。
0x01 背景
1.1 问题
我们都知道,生成式 LLM 大部分是 Decoder-only 结构,其一方面模型比较大,推理时占用的存储空间、所需的计算量都比较大,另一方面,大模型解码时是一个 Token 一个 Token 串行生成,在 batch size 为 1 时,Transformer block 中的矩阵乘都退化为矩阵乘向量操作,对于 GPU 推理来说,这是非常明显的 IO bound,导致无法充分发挥 GPU 算力。
1.2 自回归解码
当前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理阶段采用自回归采样,特点如下:
- 模型使用前缀作为输入,将输出结果处理+归一化成概率分布后,采样生成下一个token。
- 从生成第一个 Token之后,开始采用自回归方式一次生成一个 Token,即当前轮输出token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,然后解码。
- 重复执行2。在后续执行过程中,前后两轮的输入只相差一个 token。
- 直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束。
自回归解码对应的算法如下图所示。
自回归采样的缺点如下:
- 因为在生成文本时,自回归采样是逐个 token 生成的,生成下一个 token 需要依赖前面已经生成的 token,这种串行的模式导致生成速度慢,效率很低。具体参见下图。假设输出总共有 N 个 Token,则 Decoding 阶段需要执行 N-1 次 Forward,这 N-1 次 Forward 只能串行执行。
- 在生成过程中,需要关注的 Token 越来越多(每个 Token 的生成都需要和之前的 Token 进行注意力计算),计算量也会随之增大。
- 大型模型的推理过程往往受制于访存速度。因为推理下一个token的时候,需要依赖前面的结果。所以在实际使用GPU进行计算时,需要将所有模型参数以及kv-cache移至片上内存进行运算,而一般来说片上内存带宽比计算性能要低两个数量级,这就使得大模型推理是memory-bandwidth-bound的,内存访问带宽成为严重的瓶颈。
另外,大模型的能力遵循scaling law,也就是模型的参数越多其拥有的能力越强,而越大的模型自然就需要越多的计算资源。scaling law告诉我们,我们没有办法通过直接减小模型的参数量来减小访存的访问量。
为了解决推理速度慢的问题,研究人员已经进行了许多针对推理的工程优化,例如:
- 改进的计算核心实现、多卡并行计算、批处理策略等等。其中,最朴素的做法就是增大推理时的 Batch size,比如使用 dynamic batching,将多个请求合并处理,将矩阵乘向量重新变为矩阵乘操作,在 Batch size 不大的情况下,几乎可以获得 QPS 的线性提升。然而,这些方法并没有从根本上解决LLM解码过程是受制于访存带宽的问题。
- 对模型以及KV Cache进行量化,使每一个token生成过程中读取模型参数时的总比特数减小,缓解io压力。
- increasing the arithmetic intensity,即提高“浮点数计算量/数据传输量”这个比值,让数据传输不要成为瓶颈。
- reducing the number of decoding steps,即缩短解码步骤。投机解码就属于这个范畴。
0x02 定义 & 历史
2.1 投机解码
投机解码(Speculative Decoding)允许我们将在同一个用户请求内的多个 Token 一起运算。其目的和 dynamic batching 类似,也是为了将矩阵乘向量重新变为矩阵乘操作,这很适合无法获得更大 Batch size 或者只想降低端到端延时的场景。投机解码一般使用两个模型:Draft Model(草稿模型)快速生成多个候选结果,然后Target Model(目标模型)并行验证和修改,最终得到满意答案。具体而言:
- draft model用来猜测。draft model推理较快,承担了串行的工作,它以自回归的方式生成K个tokens,从而让目标模型能够并行的计算。
- target model用来评估采样结果\审核修正。target model通过并行计算多个token来从自回归模型中采样,用推理结果来决定是否使用draft model生成的这些tokens。
投机解码的算法如下图所示。
投机解码无需对输出进行任何更改,就可以保证和使用原始模型的采样分布完全相同,因此和直接用大模型解码是等价的。下图右侧,草稿模型先生成5个预测token后,将5个token一起输入给目标模型。以该前缀作为输入时,目标模型会生成若干token,然后进行验证。绿色表示草稿模型生成的token和目标模型生成的token一致,预测token通过了“验证”——这个token本来就是LLM自己会生成的结果。红色token是没有通过验证的“推测”token。第一个没有通过验证的“推测”token和其后续的“推测”token都将被丢弃。因为这个红色token不是LLM自己会生成的结果,那么前缀正确性假设就被打破,这些后续token的验证都无法保证前缀输入是“正确”的了。
2.2 发展历史
下面给出了投机解码的发展历史。
其中有两篇文章需要特殊提一下,两篇文章都算是投机解码的开山之作,其中公案我们也难以说清。
Speculative Decoding
论文“Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation”是第一篇提出 Speculative Decoding 这个词的文章,也确立了使用 draft-then-verify 这一方法加速 Auto-Regressive 生成的范式。
Speculative Decoding 希望解决的是现有的 Autoregressive 模型推理过慢的问题。下图(a)是Blockwise Decoding,其在目标自回归模型上引入了k − 1个FFN头,这些头使用共享注意力(shared attention)来预测下面k个tokken。(b)是Spec-Drafter模型,该模型是预测草稿token的独立模型,它使用不同的query来预测每个草稿token。下图上黄色部分是自回归AR模型,红色部分是新加入的模块。
Speculative Sampling
论文“Fast Inference from Transformers via Speculative Decoding”最早提出了 Speculative Sampling。此文章和上一篇文章是同时期的研究,被认为是SD的开山之作,后续许多研究都是基于此来展开。本文用 target model(目标模型)指代待加速的大模型,用 approximation model(近似模型)指代用来帮助加速大模型的小模型。
后续我们统一使用speculative decoding这个术语。
接下来,我们先对本领域的先驱之作"Blockwise Parallel Decoding"做简要分析,然后再结合两篇开山之作进行学习。
0x03 Blockwise Parallel Decoding
论文“Blockwise Parallel Decoding for Deep Autoregressive Models”提出的Blockwise Parallel Decoding是本领域的先行之作,或者说并行解码的第一个工作,所以我们仔细学习下,有助于我们理解后续脉络。Blockwise Parallel Decoding(BPD)使用多头的方式生成候选序列(一个串行序列),然后进行并行验证。
3.1 动机
BPD旨在解决Transfomer-based Decoder串行贪心解码的低计算效率问题:在序列生成时是串行的一个一个 Token的生成,计算量和生成结果所需的时间与生成的 Token 数目成正比。
我们接下来看看BPD的出发点和思路。
上图是贪心解码的展示。贪心解码效率很高,但可能无法找到全局最优,而且存在很多问题,具体如下。
- 假设输出序列的长度为 m,那么 Autoregressive Decoding 要执行 m 步才能获得最终结果,随着模型的增大,每一步的时延也会增大,整体时延也会放大至少 m 倍。
- 因为每次进行一个token生成的计算,需要搬运全部的模型参数和激活张量,这使解码过程严重受限于内存带宽。
为了克服上述限制,BPD的改进动机如下。
- 作者期望通过 n 步就可完成整个预测,其中 n 远小于 m。
- 但是如何打破串行解码魔咒,并行产生后k个token?因为语言模型都是预测下一个token,如果我们有k-1个辅助模型,每个模型可以根据输入序列跳跃地预测后2到k个位置的token。那么,辅助模型和原始模型就有可能独立运行,从而并行生成后k个token。
3.2 思路
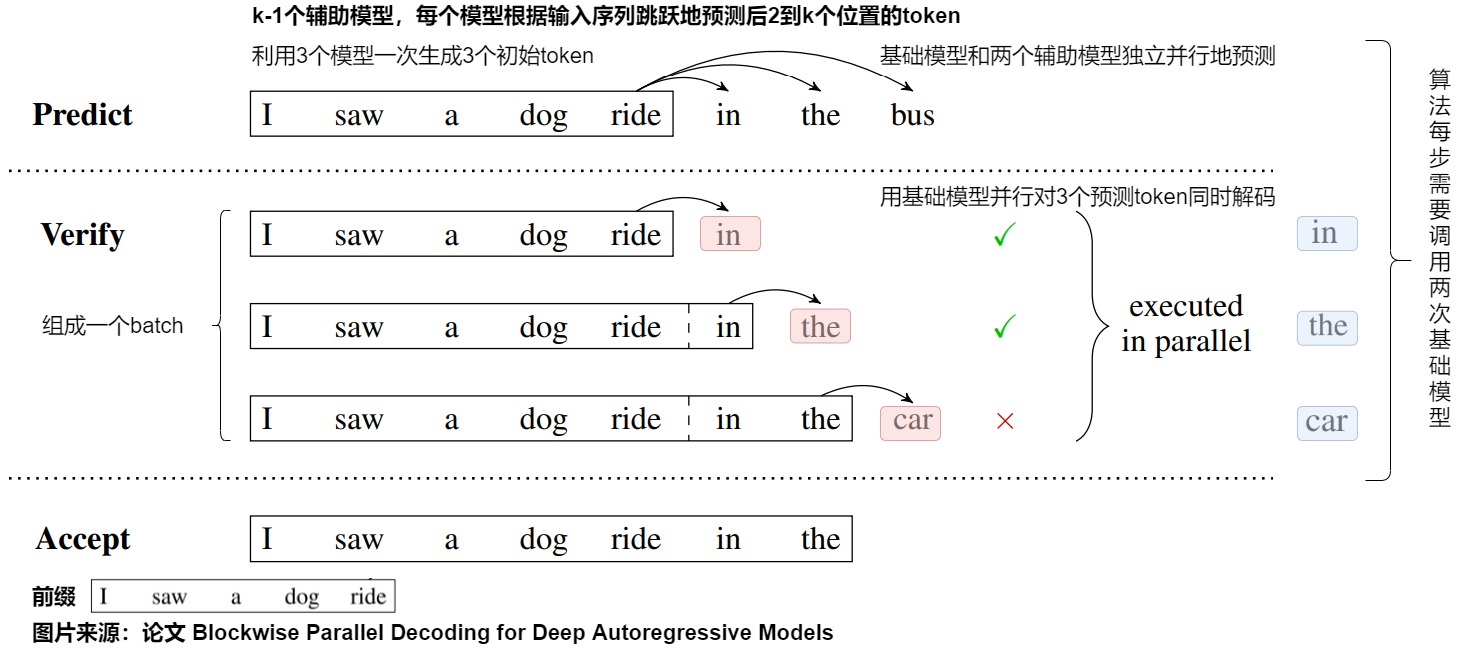
论文提出了针对深度自回归模型的并行解码技术——分块并行解码(Blockwise Parallel Decoding)方案。该方案通过训练辅助模型(通过在原始模型的Decoder后面增添少量参数),使得模型能够预测未来位置的输出(并行地预测并验证后k个token),然后利用这些预测结果来跳过部分贪心解码步骤,从而加速解码过程。具体而言,BPD提出了使用特殊drafting heads的draft-then-verify范式,其三个阶段分别是Predict、Verify和Accept阶段。
- Predict 阶段使用“原模型+k-1个辅助模型”进行k个位置token的预测。论文将模型原来的单 head(最后用于预测 Token 分布的 MLP)转换为多个 head,第一个 head 为保留原始模型的 head,用于预测下一个 Token,后面新增的 head 分别预测下下一个 Token,下下下一个 Token,相当于一次预测多个 Token。
- Verify(验证)阶段使用原模型并行地验证这k个位置上候选词所形成的几种可能。因为已经生成了多个token,因此在下一次推理的时候,即可使用原模型并行地验证这些 Token 序列(由于模型计算本身是 IO bound,并行验证增加的计算几乎不会增加推理的时延)。Verify 过程会将这些token组成batch,实现合适的attention mask,一次性获得这个k个位置的词表概率。因为第一个 head 就是原始模型的 head,所以结果肯定是对的,这样就可以保证每个 decoding step 实际生成的 Token 数是 >= 1 的,以此达到降低解码次数的目的。另外,在验证同时也可顺带生成新的需要预测的 Token。
- Accept阶段会接受验证过的最长前缀,附加到原始序列上。此阶段会贪心地选择概率最大的token,如果验证结果的token和Predict阶段预测的token相同则保留。如果不同,则后面的token预测都错误。
需要说明的是,这篇论文的工作只支持贪婪解码(Greedy Decoding),不适合其他的解码算法(而Speculative Sampling可以适配Beam Search),在不牺牲效果的情况下,有效 Token 数可能并不多。而且模型还需要使用训练数据进行微调。因此,Blockwise Parallel Decoding=multi-draft model +top-1 sampling+ parallel verification。受此启发,后续提出的Speculative Sampling方法也使用小模型并行预测,大模型验证的方式解决相同的问题。
3.3 架构
BPD提出了多头并行解码机制。除了原始模型 p 外,在 Predict 阶段还有几个辅助模型 p2,...,pk 。用这些模型来辅助预测。但是我们会面临一个问题:如果这些辅助模型采用和原始模型 p 同样的结构并单独训练,那么在 Predict 阶段的计算量就是生成一个 Token 的 K 倍。即使忽略 Verify 阶段,理想情况下整个训练任务的计算量也没有降低。而且这K个模型对于内存的占用将是非常惊人的。因此,论文并没有真的构造出k-1个辅助模型,即p2,...,pk 并非是独立的原始模型的副本。论文是对原始模型略作改造,让这些辅助模型与原始模型 p1 共享 backbone,然后增加一个隐藏层,针对每个模型 p1,...,pk 都有独立的输出层。这样就就可以让新模型具备预测后k个token的能力,能保证 Predict 段实际的计算量与之前单个 Token 预测的计算量基本相当。
具体模型架构如下图所示,在原始模型之上一共增加了三层(从下至上):
- 在原始模型的最后一个 Transformer Decoder 层之后先加上一个隐层,它的输入是(batch_size, sequence_length, d_model),输出是(batch_size, sequence_length, k* d_model)。
- 在隐层之后会额外加上几个 head,分别为 p2,...,pk。Transformer Decoder 层输出的 logit 会先传给隐层进行投影,投影后的输出会分别传给这几个头。这些头的计算结果会分别再与原始模型的logit做残差连接。每个头负责预估一个token,这k个头的输出就是k个不同位置token的logits。头1 负责预估 next token, 头2 负责预估 next next token, 以此类推。
- 最后再将结果送入到词表投影层(包括一个线性变换和一个Softmax),预估每个词的概率分布,最终通过某种采样方法生成token。这个词表投影层是在多Head之间共享的。
主干网络 + 头1(下图红色)是原模型或者说基础模型,也就是预训练的模型。其他Head是论文说的辅助网络(auxiliary model)(蓝色和绿色分别是两个辅助网络)。既然可以根据输入序列预测下一个 Token,那么也就可以根据同样的序列预测下下一个,下下下一个 Token,只是准确率可能会低一些而已,这样就可以在 Decoding step 的同时额外生成一个候选序列,让基础模型在下次 Decoding step 来验证即可。
3.4 训练
改造后的模型还需要使用训练数据进行训练。由于训练时的内存限制,论文无法使用对应于k个project layer输出的k个交叉熵损失的平均值作为loss。而是为每个minibatch随机均匀选择其中的一个layer输出作为loss。
训练FFN的参数可以使用如下几种方式:
- Frozen Parameters:将原始模型参数冻结,只更新那些新加入的FFN层参数。这样预测下一个token肯定是准确的,但可能影响辅助模型预测的准确性。
- Finetuning:以原始参数为初始化值对全部参数进行微调,这可能会提高模型的内部一致性,但在最终性能上可能会有所损失。
- Distillation:蒸馏很适合并行解码,因为teacher和student都有相同的结构。蒸馏数据是原始模型用相同的超参数但不同的随机种子进行beam search产生的。
3.5 步骤
下图展示了blockwise decoding的三个阶段,分别是Predict、Verify和Accept阶段。
我们基于上图进行详细解读,假设要生成的序列长度为
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |











 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



