在机器学习的世界里,集成学习(Ensemble Learning)是一种强大的技术,它通过组合多个模型来提高预测性能。
集成学习通过组合多个基学习器的预测结果,获得比单一模型更优秀的性能。其核心思想是"三个臭皮匠顶个诸葛亮",主要分为两大流派:Boosting(提升)和Bagging(装袋)。
本文将重点解析这两种方法的原理,并通过实战演示它们的应用。
1. Boosting:从错误中学习
Boosting的核心思想是串行训练:每个新模型都专注于修正前序模型的错误。
它的工作流程类似于"错题本学习法":
- 训练第一个基学习器
- 给预测错误的样本增加权重
- 基于新权重训练下一个学习器
- 重复步骤2-3,最终加权组合所有预测结果
最常见的Boosting算法是AdaBoost和Gradient Boosting。
下面我们使用Gradient Boosting来演示。- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import GradientBoostingClassifier
- from sklearn.metrics import accuracy_score
- # 生成一个简单的二分类数据集
- X, y = make_moons(n_samples=300, noise=0.25, random_state=42)
- X_train, X_test, y_train, y_test = train_test_split(
- X, y, test_size=0.3, random_state=42
- )
- # 使用 Gradient Boosting
- gbc = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
- gbc.fit(X_train, y_train)
- # 预测并计算准确率
- y_pred = gbc.predict(X_test)
- accuracy = accuracy_score(y_test, y_pred)
- print(f"梯度 Boosting 准确率: {accuracy:.2f}")
- # 输出结果:
- '''
- 梯度 Boosting 准确率: 0.92
- '''
- # 绘制决策边界
- def plot_decision_boundary(model, X, y):
- h = 0.02
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
- Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
- Z = Z.reshape(xx.shape)
- plt.contourf(xx, yy, Z, alpha=0.4)
- plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k", marker="o")
- plt.title("决策边界")
- plt.show()
- plot_decision_boundary(gbc, X, y)
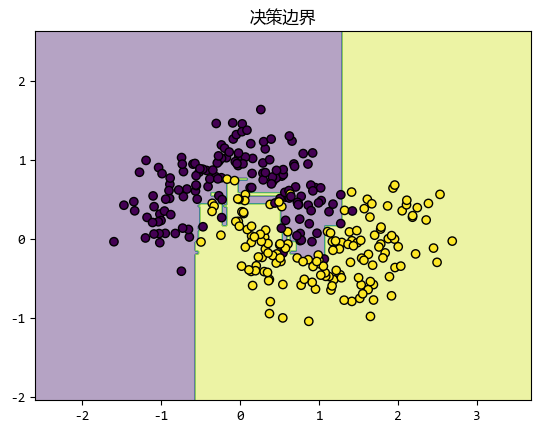
在这个例子中,我们生成了一个简单的二分类数据集,并用 Gradient Boosting 进行训练。
可以看到,模型能够很好地拟合数据,并且决策边界也很清晰。
2. Bagging:民主投票机制
Bagging的核心是并行训练+随机化。
通过随机抽样生成多个不同的数据子集,然后在每个子集上训练一个模型,最后把所有模型的预测结果汇总起来,得到最终的预测。
具体来说:
- 随机抽样:从原始数据集中随机抽取多个子集(有放回抽样)。
- 训练模型:在每个子集上训练一个模型(通常是决策树)。
- 汇总结果:对于分类任务,通过投票决定最终结果;对于回归任务,取平均值。
随机森林(Random Forest)是 Bagging 的一个经典应用,它在训练决策树时还会随机选择特征子集,进一步增加模型的多样性。
下面我们用scikit-learn的RandomForestClassifier来实现一个随机森林模型。- from sklearn.ensemble import RandomForestClassifier
- # 使用 Random Forest
- rf = RandomForestClassifier(n_estimators=100, random_state=42)
- rf.fit(X_train, y_train)
- # 预测并计算准确率
- y_pred_rf = rf.predict(X_test)
- accuracy_rf = accuracy_score(y_test, y_pred_rf)
- print(f"随机森林 Bagging 准确率: {accuracy_rf:.2f}")
- # 输出结果:
- '''
- 随机森林 Bagging 准确率: 0.92
- '''
- # 绘制决策边界
- plot_decision_boundary(rf, X, y)
在这个例子中,我们同样使用了之前生成的二分类数据集。
随机森林通过多个决策树的组合,能够更好地处理复杂的数据分布,并且具有很强的抗过拟合能力。
3. 偏差-方差图:理解模型性能的关键
在集成学习中,偏差-方差图是一个非常有用的工具,它可以帮助我们理解模型的性能。
- 偏差(Bias):模型对数据规律的拟合能力。偏差越高,模型越简单,可能欠拟合;偏差越低,模型越复杂,可能过拟合。
- 方差(Variance):模型对数据噪声的敏感程度。方差越高,模型对训练数据的波动越敏感,容易过拟合;方差越低,模型对数据波动不敏感,可能欠拟合。
对于Boosting和Bagging:
- Boosting:通常会降低偏差,但可能会增加方差。因为 Boosting 不断调整模型以拟合数据,容易对噪声过于敏感。
- Bagging:通常会降低方差,但对偏差的影响较小。因为 Bagging 通过随机抽样和投票,能够减少模型对数据波动的敏感性。
通过偏差-方差图,我们可以更好地选择合适的集成学习方法。
如果数据噪声较大,Boosting可能会过拟合;而如果数据分布复杂,Bagging可能会欠拟合。
4. 总结
Boosting和Bagging是两种非常强大的集成学习方法。
这两种集成学习方法的 对比和选择建议 如下表:
特性BoostingBagging训练方式串行并行样本使用加权调整自助采样主要优势降低偏差降低方差过拟合风险较高较低典型应用场景复杂关系建模高噪声数据处理Boosting通过弱学习器的接力赛,逐步改进模型;Bagging通过随机抽样和投票,降低模型的方差。
通过scikit-learn,我们可以很容易地应用这两种方法。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



